


Ship Happens, Week 7: When you should not A/B test, Deep Research, GPT-5 and LLM text fatigue
A roundup of topics and articles for the week.

Happy Friday everyone! Welcome back to Ship Happens, your weekly product manager newsletter.
I'm using this newsletter to share at least three things l've come across this week to help you build better product. Subscribe so you don't miss these when they come out:
On to this week's thoughts and updates!
1. Here’s when you should not run A/B tests
Don’t get it twisted okay, A/B testing is USUALLY the gold standard for understanding the effects of what you ship in the overall product experience you’re working on. When performed correctly, it can give you one of the most accurate views into feature effects and control for many external factors.
Unfortunately though, A/B testing is much more complicated than just splitting your traffic 50/50 for control vs. variant to see what works. In the book Trustworthy Online Controlled Experimentation that we talked about in Week 2, they cover what’s required to run a quality test in depth. Here’s a sample of the things that need to happen for test results to be reliable:
Tests need to be evenly bucketed, avoiding the dreaded Sample Ratio Mismatch (SRM)
Tests must be designed to bucket at the correct moment in the experience. For example, if you’re introducing a new button on the product page, users must be assigned into control or variant at minimum on the page where the user would encounter the new button. Best case, the assignment is made once the user would actually see the button (this is called triggering)
The duration a test needs to run depends on things like how big the conversion rate of your product is, the level of change you want to observe, and if the number is binarized or not.
Here’s a handy calculator for understanding that I use all the time.
Depending on the volume needed for an accurate read in the calculator for each arm of the test and your site traffic, that will determine how long your test needs to run.
If your conversion rate is really small, the test will need to run FOREVER.
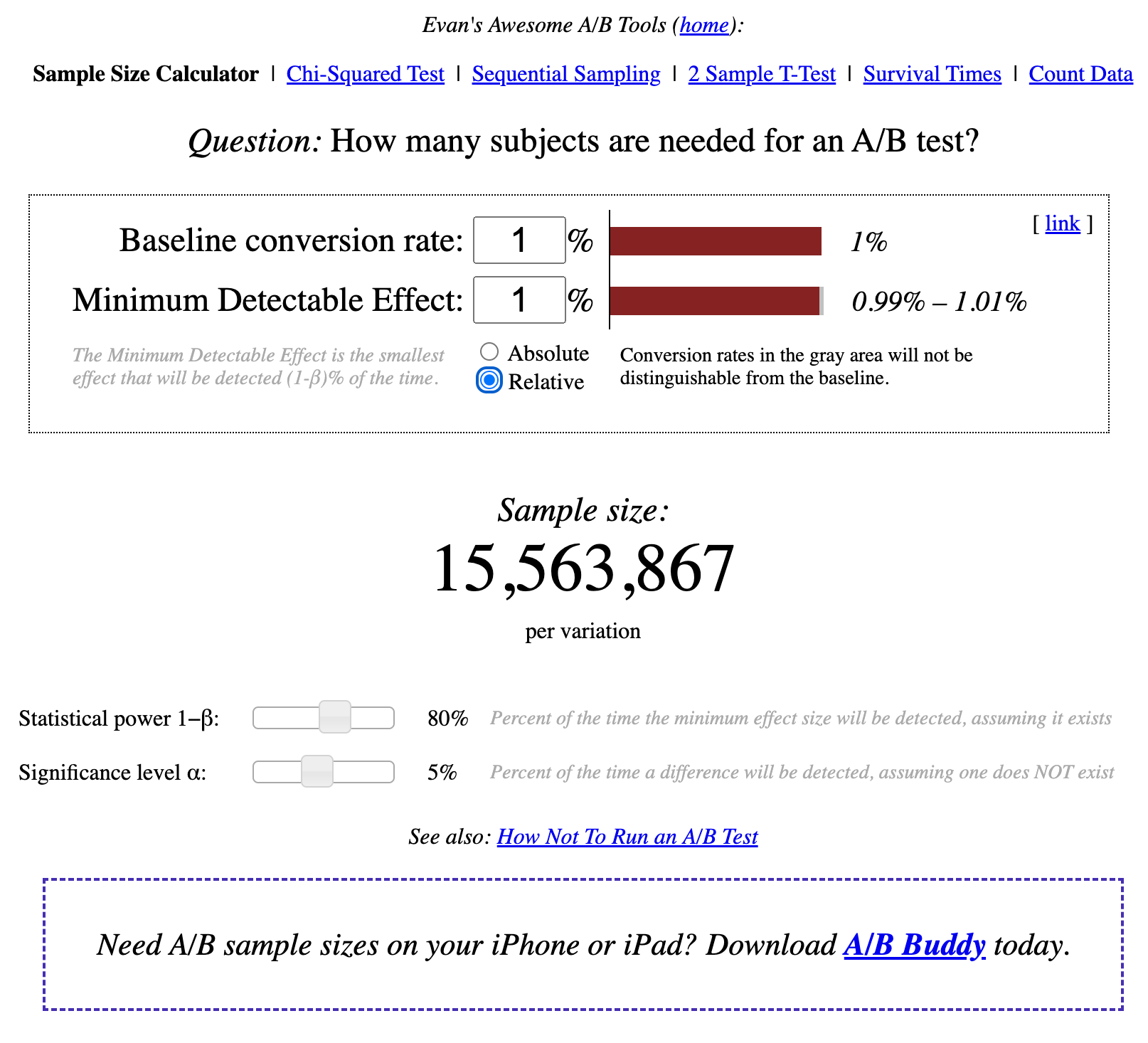
Seasonality and events during the testing window matter. So if there are certain events that are happening during your test that would affect the treatment(s) in the test, you have to change your timing or duration to account for it.
All of this is just to say that there are many things you’d want to ship that won’t work with all of the requirements above. Or they just don’t make sense to go through all of the trouble above to run them.
Based on the above, here are things that I would consider not A/B testing
If the “A/B test” it’s actually a bug fix
Look, if a button’s not clickable, that’s a bug, NOT an A/B test. Do yourself and your poor users a favor and just fix it. You shouldn’t get brownie points for measuring the A/B test impact of fixing it. And if you do…maybe you’re in the wrong place?!
If the “A/B test” is an area where there is very low traffic volume

If you’re considering running an A/B test in an area of the product that gets 100 users/month and your conversion rate is 1%, the calculator above is going to tell you that for a +/- 1% relative change, you’re going to need to run the test for 25,000 YEARS.
Why would you do that?!
In this case, it’s probably better to make sure everything is instrumented to monitor the change properly and run a pre-post after you ship the change. You’ll get a good sense of what happened, you won’t have to wait until your 250th life to know the results, and you won’t get a bogus result that looks real but is really just statistical noise.
If the “A/B test” is a clear improvement and isn’t worth the time required to get an accurate result
This sounds like a bug, but it’s actually more like a risk/reward type decision. Let’s say you have a flow where 100 users/month go through it, your conversion rate is 1%, and merging one of the steps into the other step after it, the UX remaining as-is, would reduce friction significantly in the flow. Is it worth waiting 12,500 years or getting a bogus result that’s going to point you in the wrong direction? Probably not. Instrument it, make the change, eyeball how you did, move on.
So not anything should be A/B tested. I mean, don’t YOLO it. You’ll notice above that in all cases I emphasize good monitoring and evaluating the performance of what you shipped all the same.
A/B testing is just like any other tool in the tool belt. You should use the right tool for the right job.
2. Deep Research is straight up magic and worth more of the $200/month than Operator

I’m sure Operator is going to be amazing one day and do all of the agent-like things we’ve come to expect from this age of AI.
But it’s terrible right now. It’s slow as hell, I can do what it tries to do often in a tenth of the time.
Unfortunately that’s why I paid OpenAI $200/month for it’s Pro feature set. And I was a bit upset about that, even knowing that it will get better over time. But a really nice side effect of forking over the money was being able to use Deep Research.
Deep Research is the bomb.com. I used it personally to explore questions like how the B2B and D2C spaces of the software industry have evolved over the last 15 years or what benchmarks for mobile web e-commerce experiences look like for the world-class e-commerce experiences out there. Each time it would research hundreds of sites, synthesize the information, “think” over it and compile a simple research report that was comprehensive and uber-useful.
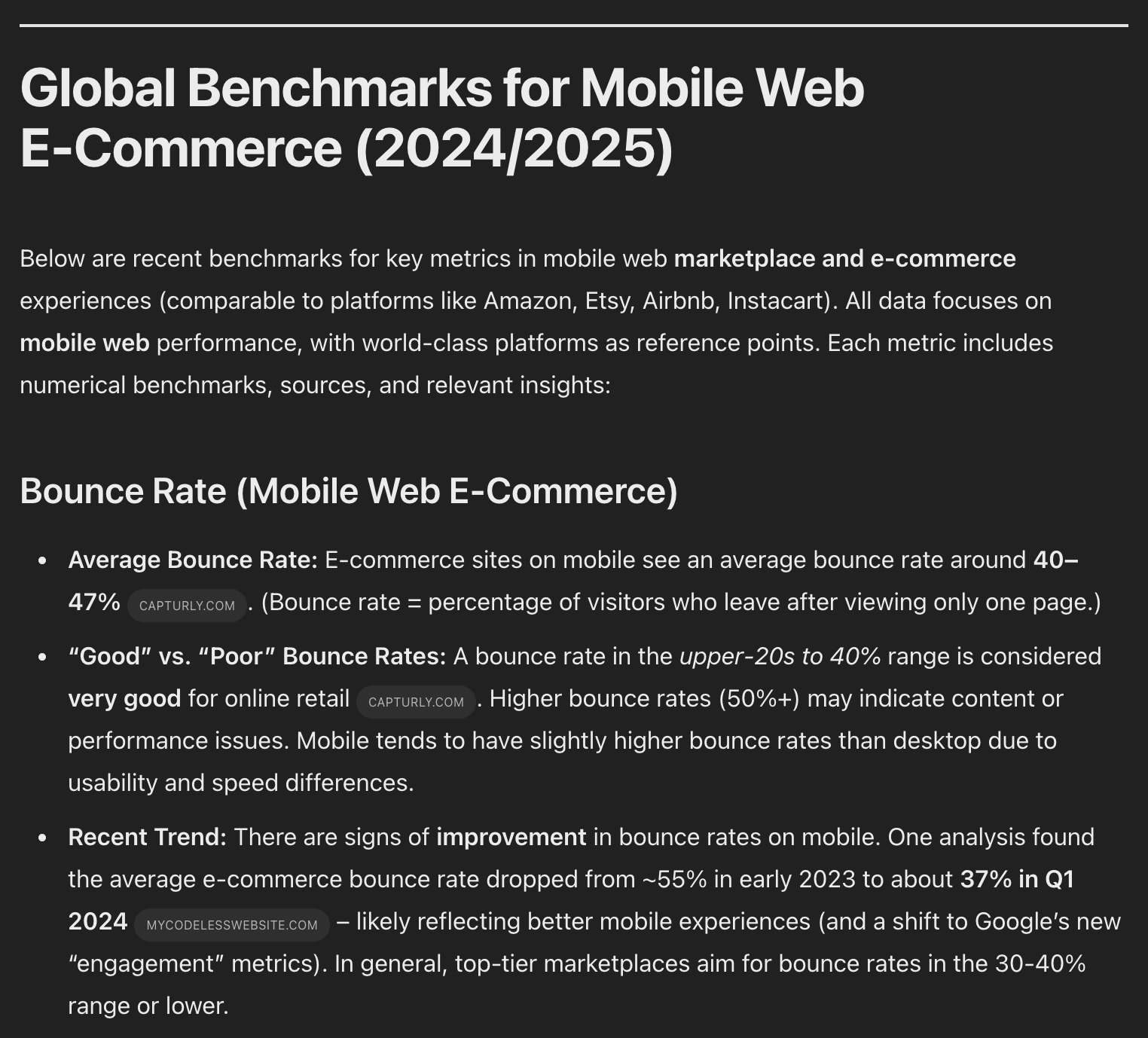
Rather than me scouring the internet for hours finding that data and compiling it into something legible, Deep Research did all of that for me in 10 minutes while I figured out how best to communicate it.
If that’s not a glimpse into a very bright future, I don’t know what is. Highly recommend giving it a go.
3. Did ChatGPT Voice Mode inform what’s coming with GPT-5?
Sam Altman gave us this gem of a tweet/X on the future ChatGPT roadmap:

The part about non-chain-of-thought is clearly a response to DeepSeek which we talked about in Week 5. What’s funny about this though is that the way OpenAI wants GPT-5 to work is similar to the way Voice Mode already works today.
I’ve been increasingly using Voice Mode, I’ve found it to be way more convenient than chatting. And when I use it, I rarely put it into Search Mode. It usually determines I need to latest data for my query and goes out to fetch the latest info to infuse into its response.
If you want things to work this way already, I’d start with Voice Mode. Hopefully it will be more of a model for how ChatGPT evolves. Because yeah that menu of options is really gross.
4. Is LLM text fatigue setting in for anyone else?
I realize it’s the simplest way to get to market with AI. Here’s an example from Particle News, where it’s reformatted but basically an LLM text output:
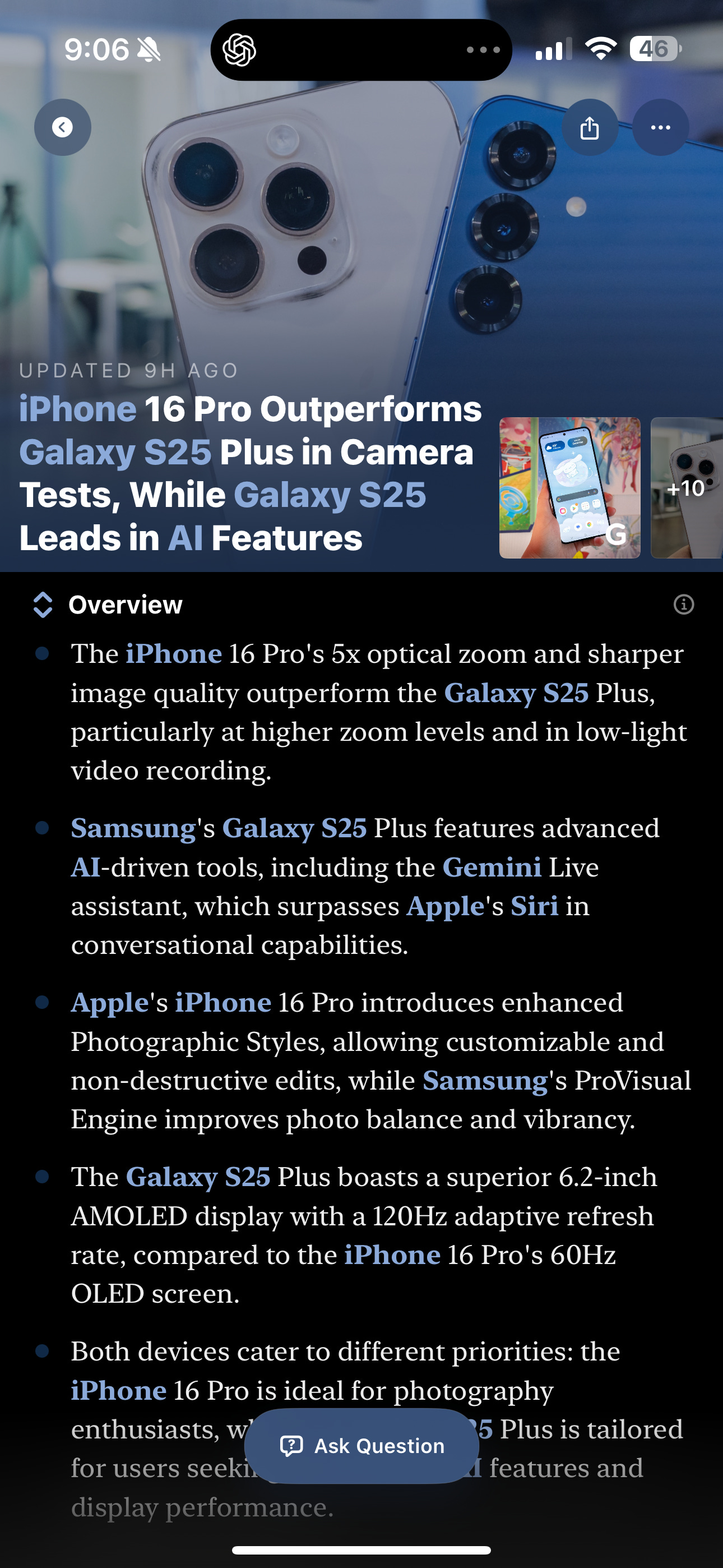
Don’t get it twisted, I enjoy Particle News and LLMs as much as the next tech nerd. But right now it’s like everywhere I turn I get flooded with AI-generated text. It’s solving an amazing problem set, but I am really looking forward to the day when the pendulum swings back towards well-rationalized UI-oriented experiences. And I hope I can be part of that change because my eyes are STRESSED.
Is it just me?!
That's it for this week!
If you've found this helpful, please consider showing your support by subscribing:
And please consider supporting by becoming a paid subscriber at $5/month or $50/year. I don’t require it to get great value out of the newsletter, but it does provide great motivation to keep going. So consider going paid, you can participate in the paid subscriber chat and keep this sucker going!
Finally, share with someone else that you think would find this useful:
I’ll be back around this time next week with more useful product manager things!